PyCaret
PyCaret是一个开源的低代码机器学习库和内置 Python 的端到端模型管理工具,用于自动化机器学习工作流。它的易用性、简单性以及快速高效地构建和部署端到端机器学习管道的能力将让您惊叹不已。
PyCaret 是一个替代的低代码库,可以用几行代码替换数百行代码。这使得实验周期呈指数级快速和高效。
PyCaret 简单易用。 在 PyCaret 中执行的所有操作都按顺序存储在一个完全自动化的管道中,以便进行部署。 无论是插补缺失值、单热编码、转换分类数据、特征工程,甚至是超参数调优,PyCaret 都能自动完成所有操作。要了解有关 PyCaret 的更多信息,请观看此 1 分钟视频。
KNIME
KNIME分析平台是用于创建数据科学的开源软件。KNIME 直观、开放且不断集成新开发成果,使每个人都能理解数据、设计数据科学工作流程和可重用组件。
KNIME Analytics 平台是数据科学中最受欢迎的开源平台之一,用于自动化数据科学过程。KNIME 在节点存储库中有数千个节点,允许您将节点拖放到 KNIME 工作台中。相互关联的节点集合创建一个工作流,该工作流可以在本地执行,也可以在将工作流部署到 KNIME 服务器后在 KNIME Web 门户中执行。
安装
在本教程中,您将需要两件事。第一个是KNIME分析平台,这是一个桌面软件,您可以从中下载这里.其次,你需要 Python。
开始使用 Python 的最简单方法是下载 Anaconda Distribution。要下载,点击这里.
安装 KNIME Analytics Platform 和 Python 后,您需要创建一个单独的 conda 环境,我们将在其中安装 PyCaret。打开 Anaconda 提示符并运行以下命令:
***# create a conda environment*
**conda create -name knimeenv python=3.6
***# activate environment*
**conda activate knimeenv
***# install pycaret*
**pip install pycaret
现在打开KNIME分析平台,转到”文件”→”安装KNIME扩展”→”KNIME & Extensions”→然后选择KNIME Python Extension并安装它。
安装完成后,转到 KNIME → Python →”文件”→首选项,然后选择 Python 3 环境。请注意,在我的例子中,环境的名称是”powerbi”。如果您已按照上述命令操作,则环境的名称为”knimeenv”。
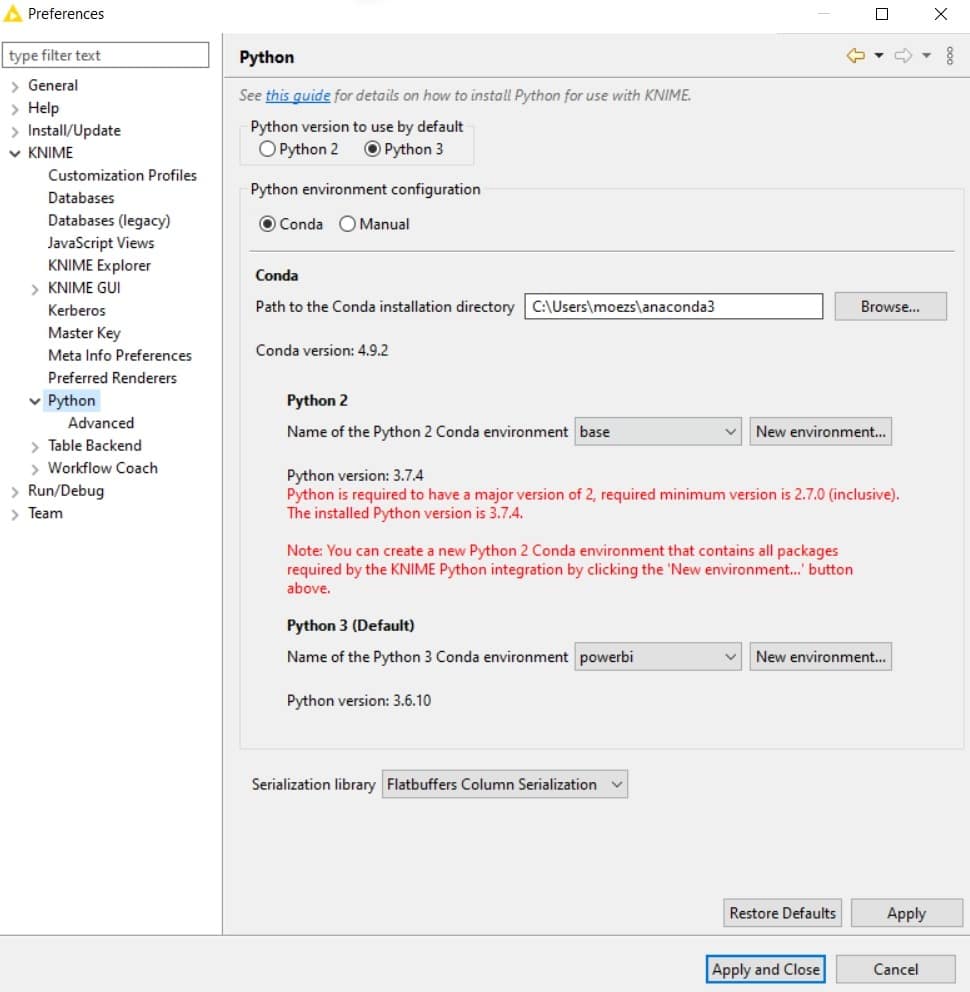
👉我们现在已经准备好了
单击”新建 KNIME 工作流程”,将打开一个空白画布。
在左侧,有一些工具可以拖放到画布上,并通过将每个组件相互连接来执行工作流。左侧存储库中的所有操作都称为节点。
数据
在本教程中,我使用了 PyCaret 存储库中名为”insurance”的回归数据集。您可以从以下位置下载数据这里.

示例数据集
我将创建两个单独的工作流。第一个用于模型训练和选择,第二个用于使用经过训练的管道对新数据进行评分。
👉 模型训练与选拔
让我们首先从 CSV Reader 节点读取 CSV 文件,然后读取 Python 脚本。 在 Python 脚本中执行以下代码:
**# init setup, prepare data**
from pycaret.regression import *
s = setup(input_table_1, target = ‘charges’, silent=True)
**# model training and selection
**best = compare_models()
**# store the results, print and save**
output_table_1 = pull()
output_table_1.to_csv(‘c:/users/moezs/pycaret-demo-knime/results.csv’, index = False)
**# finalize best model and save**
best_final = finalize_model(best)
save_model(best_final, ‘c:/users/moezs/pycaret-demo-knime/pipeline’)
该脚本从 pycaret 导入回归模块,然后初始化 setup 函数,该函数自动处理train_test_split和所有数据准备任务,例如缺失值插补、缩放、特征工程等。 compare_models使用 kfold 交叉验证训练和评估所有估计器,并返回最佳模型。pull 函数将模型性能指标作为 Dataframe 调用,然后将其作为 results.csv 保存在本地驱动器上。最后,save_model将整个转换管道和模型保存为 pickle 文件。
培训工作流程
成功执行此工作流后,将在定义的文件夹中生成 pipeline.pkl 和 results.csv 文件。
这是结果.csv包含的内容:
这些是所有模型的交叉验证指标。在这种情况下,最好的模型是 Gradient Boosting Regressor。
👉 模型评分
现在,我们可以使用 pipeline.pkl 对新数据集进行评分。由于我没有单独的”insurance.csv”数据集,因此我将做的是从同一文件中删除目标列,只是为了演示。
评分工作流程
我使用了“列过滤器“节点来删除目标列,即费用。在 Python 脚本中,执行以下代码:
**# load pipeline
**from pycaret.regression import load_model, predict_model
pipeline = load_model(‘c:/users/moezs/pycaret-demo-knime/pipeline’)
**# generate predictions and save to csv**
output_table_1 = predict_model(pipeline, data = input_table_1)
output_table_1.to_csv(‘c:/users/moezs/pycaret-demo-knime/predictions.csv’, index=False)
成功执行此工作流后,它将生成预测 .csv。
我希望您会欣赏 PyCaret 的易用性和简单性。当在像 KNIME 这样的分析平台中使用时,它可以为您节省大量编码时间,然后在生产中维护该代码。我用不到 10 行代码就使用 PyCaret 训练和评估了多个模型,并部署了一个 ML Pipeline KNIME。