人工智能具有推理能力,并以 Python、SQL 和 R 等语言生成功能代码,它们可以通过数据分析提供令人印象深刻的价值。但是他们能取代数据分析师吗?
人工智能可以做什么样的数据分析?
我们已经知道 ChatGPT 是最通用的 AI 工具,其插件使其几乎可以做任何事情。它可以生成 Python、R 和许多其他语言的功能代码,以及复杂的 SQL 查询。可以想象,结合这些功能将允许您将 AI 用于数据分析工作的几乎每个部分。
用例包括:
- 查询
- 清洗等加工
- 可视 化
在处理数据时,Julius AI(用于 csv 文件)或 BlazeSQL(用于 SQL 数据库)等专用工具是专门为此目的而设计的。与 ChatGPT 不同,这些工具不需要您在每次打开它们时上传/连接并解释您的数据。
ChatGPT 可以对 csv 文件进行一些快速分析,但大多数公司将数据存储在专用网络内的 SQL 数据库中。尽管如此,专用工具可以连接到这些受保护的 SQL 数据库,并通过查询数据库和可视化结果来回答您的问题。
人工智能如何取代数据分析师?
数据分析就是从数据中获取见解,数据分析师和数据科学家是具有技术技能的人,可以为利益相关者提供他们需要的见解。但情况发生了变化,现在人工智能工具可以成功完成一些以前只能由数据分析师和数据科学家完成的任务。
从理论上讲,没有技术技能的业务利益相关者现在可以将他们的数据连接到人工智能工具,并提出诸如”获取按产品分组的年度前 3 种产品的月收入”等请求。然后,人工智能可以抓取数据,甚至将其可视化。用户只需花几秒钟写出请求。如果他们问过一个人类同事,他们可能在几天或更长时间内都得不到答案。

对于数据分析师来说,看到这样的图像既令人惊讶又令人担忧,但取代数据分析师和数据科学家并不是那么简单。简单地运行 SQL 查询并绘制结果只是他们工作的一部分,即使这样,AI 也并不总是可靠地完成。它可能在上面的屏幕截图中起作用,但是如果结果是错误的,即使它看起来还可以,该怎么办?
听起来是时候谈谈人工智能处理数据的一些局限性了。
局限性#1:AI幻觉
大多数使用过 ChatGPT 和类似工具的人都听说过”幻觉”一词。当你问他们一些他们不知道的事情时,他们有时会编造一些东西。
这些幻觉的原因很简单:LLM 就像非常先进的自动完成算法。他们根据训练的数据返回对话中最有可能的下一条消息。得益于高质量的数据集和先进的训练技术,这种”自动完成”效果非常好,这些工具可以以非常高质量的结果满足复杂的请求。不幸的是,当他们遇到训练数据没有为他们做好准备的情况时,最有可能的下一条消息实际上可能没有多大意义。
如果它生成了一些运行的代码,但代码返回了错误的数据,该怎么办?使用 AI Data Analyst 的业务利益相关者可能不知道结果是错误的,但由于他们不理解代码,他们看不到错误。
限制 #2:业务信息。
通常,当新的数据分析师开始在一家公司工作时,他们必须了解某些列和值的含义。这是因为数据模型是由业务部门设计的。你不能只分析数据而不了解数据的来源,因为常识不足以理解大多数数据库。

像 BlazeSQL 这样的 AI 工具确实允许您包含这些信息供 AI 使用,但需要数据分析师或数据科学家来保持这些信息的最新状态。
局限性#3:有时,人工智能只是卡住了。又名”盲点”
您可能已经看到 ChatGPT 卡在一个非常基本问题上的例子。这些问题通常很容易回答,但需要人工智能以一种它不太擅长的方式进行推理。

我们可以称这些情况为”盲点”,它们也存在于编写代码中。前任。AI 在生成 SQL 查询时的一个常见盲点是使用子查询。AI 模型通常会生成尝试从子查询中选择列的查询,即使该列在子查询中不存在。
WITH recent_orders AS (
SELECT
customer_id,
MAX(order_date) AS latest_order_date
FROM
orders
GROUP BY
customer_id
)
SELECT
customer_id,
product_id, -- (This column is not defined in the subquery)
latest_order_date
FROM
recent_orders即使指出了错误,他们再次尝试时也经常会犯同样的错误。
局限性#4:AI模型同意太多
人工智能模型往往会同意你的观点,即使你错了。当 AI 模型应该扮演专家的角色时,这可能是一个巨大的问题,因为当你错了时,专家应该能够纠正你。
限制 #5:输入长度
一个人可能会花费数月时间了解一个项目和数据库,收集大量重要信息。另一方面,LLM 通常具有”令牌限制”,这意味着它只能接受一定数量的输入。
当涉及到复杂的任务时,这种输入长度(又名”令牌限制”)通常是有限制的。你怎么可能把这几个月的学习提炼成几页,并将其融入人工智能模型中?
广泛可用的 GPT-4 版本,仅限于 12 页的输入 + 输出。请记住,数据分析师将参加数小时的会议,并阅读文档或报告。所有输出(代码和 GPT-4 的解释)都需要从 12 页中减去,因为限制包括输出,而不仅仅是输入。
这意味着一个需要大量学习和探索的重大数据分析项目根本不可行。
局限性#6:软技能
最后但并非最不重要的一点是,ChatGPT 和其他 AI 聊天机器人是……只是聊天机器人。人际互动和软技能是数据项目的重要组成部分。无论是获得信任、处理办公室政治,还是解释非语言交流。这些元素对于成功与利益相关者合作和完成项目至关重要。
下一步是什么?
正如你所看到的,人工智能有许多局限性,使它无法成为一个完全有能力的数据分析师。上面的列表只包含一些主要限制,但在实际更换数据专家时还有很多其他大障碍。换句话说,你不需要担心人工智能会取代你!
话虽如此,人工智能已经对数据分析师和数据科学家产生了重大影响。它可能并不完美,但它已经提供了令人难以置信的价值。
利用 AI 加快工作速度
编写代码(无论是 Python、SQL 还是 R)都可能非常耗时。这些 AI 工具可能不是 100% 准确的,但它们在很多时候仍然运行良好。快速查看他们生成的内容通常比从头开始做所有事情快 10 倍。
在人工智能挣扎或经常犯错的情况下,从头开始可能更快。在其他情况下,生产力的大幅提高值得偶尔进行调试工作。重要的是尝试不同的工具,了解它们的优缺点,并相应地将它们集成到您的工作流程中。
未来呢?
事情进展得非常快,所以目前的一些限制不一定是一个长期的因素。现在尤其如此,因为人工智能工具正在被这么多人使用,因为他们从用户那里学习。这些交互用于训练模型,每天有数百万次交互。
ChatGPT 拥有有史以来增长最快的用户群,它从该用户群中学习。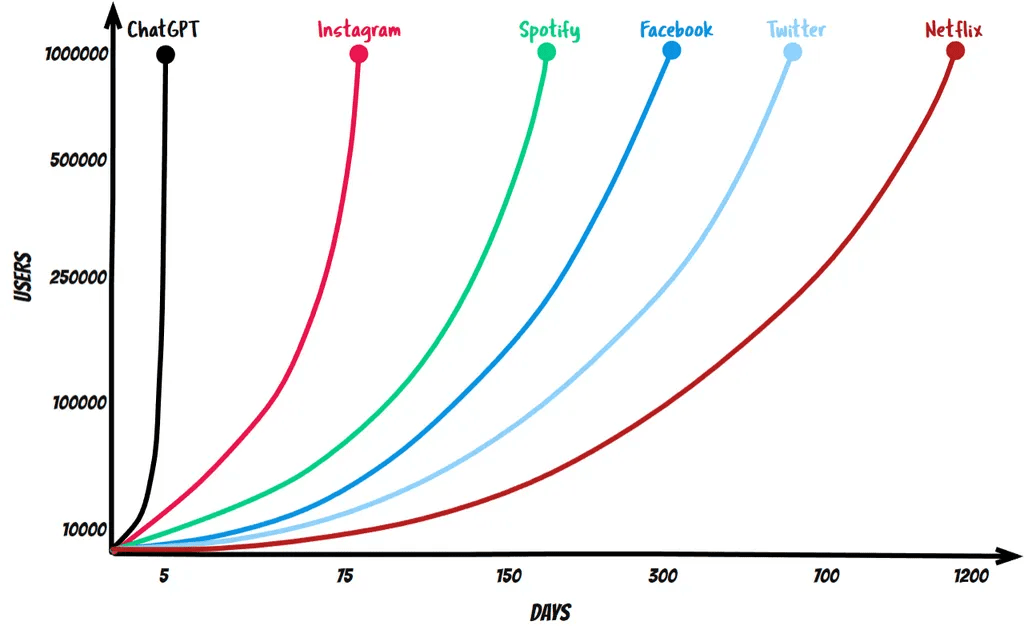
随着 Claude、Bard 等竞争对手的加入,我们一定会很快看到一些巨大的改进。
为这些变化做好准备很简单,只需留意新工具并尝试它们即可。这样,您就会了解它们的优势和劣势,并可以确保您利用最新技术并随着技术的发展而进行调整。
在这一点上,需要关注的一些工具包括:
BlazeSQL(适用于 SQL 数据库)
ChatGPT 高级数据分析(适用于 csv 和其他文件)
Pandas AI(将生成式 AI 添加到 pandas 库)